数据降维
# 数据降维
# 1、作用
数据降维是采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中,即将多列数据融合为更少列数据,且这些少列数据能够保留原数据的绝大部分有效信息。数据分析中存在部分变量是没有意义的,当这些无意义变量参与进分析的时候反而会对分析结果造成不利的影响,就可以进行降维处理;又或者想要对敏感隐私数据进行保护,也可进行降维来对数据进行变形整合。
# 2、输入输出描述
输入:至少两个定量变量(假设变量数为N)。
输出:新生成降维后的M个变量序列(M<N)。
# 3、案例示例
案例:在数据分析前,理论研究收集到10个变量(X1-X10)的信息,现需要将这10个变量进行降维,并且降维后的变量能够保留原本数据中绝大部分有效信息。
# 4、案例数据

数据降维案例数据
# 5、案例操作
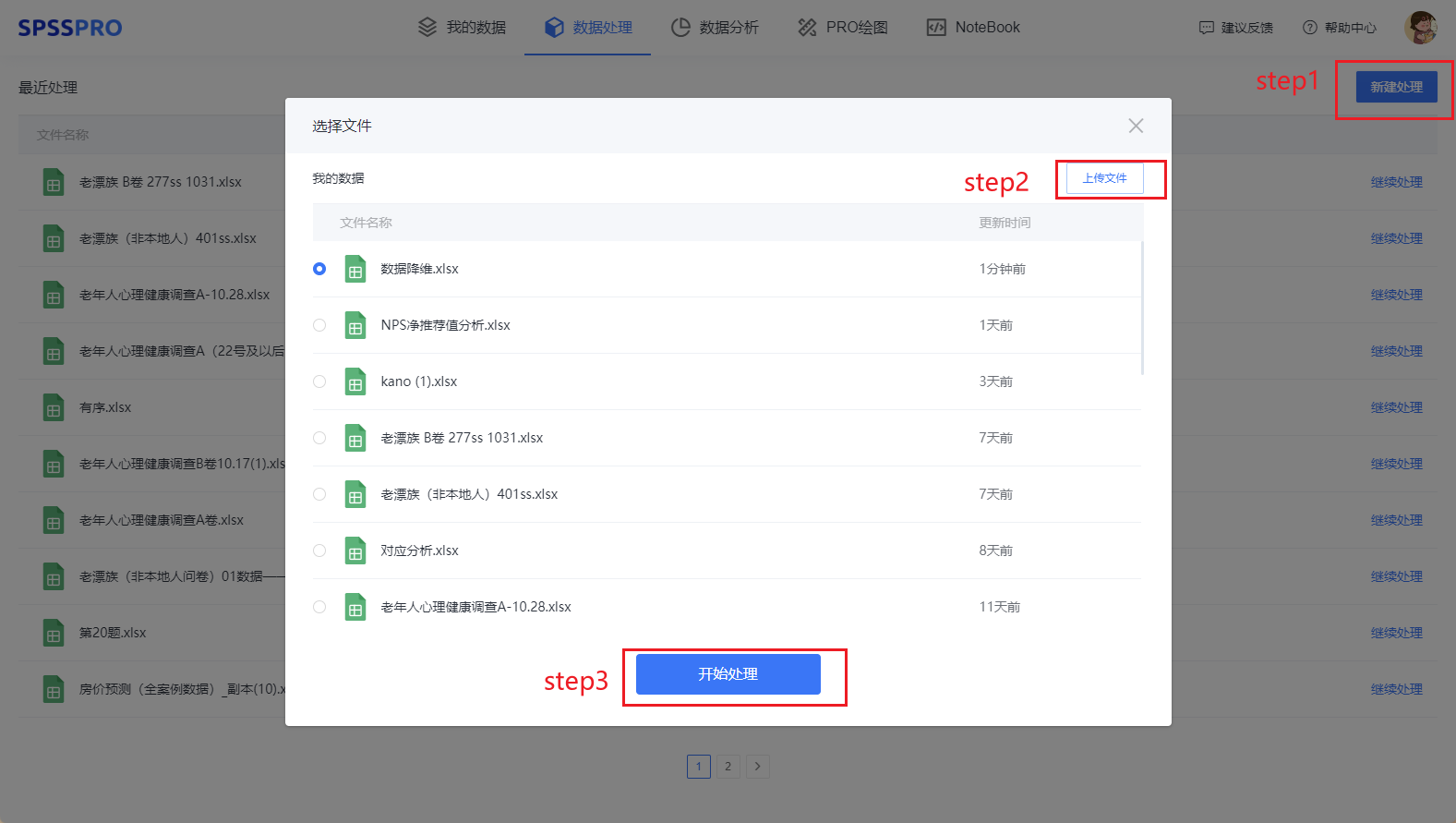
Step1:在“数据处理”模块新建处理;
Step2:上传文件;
Step3:选择对应数据打开后进行预览,确认无误后点击开始处理;
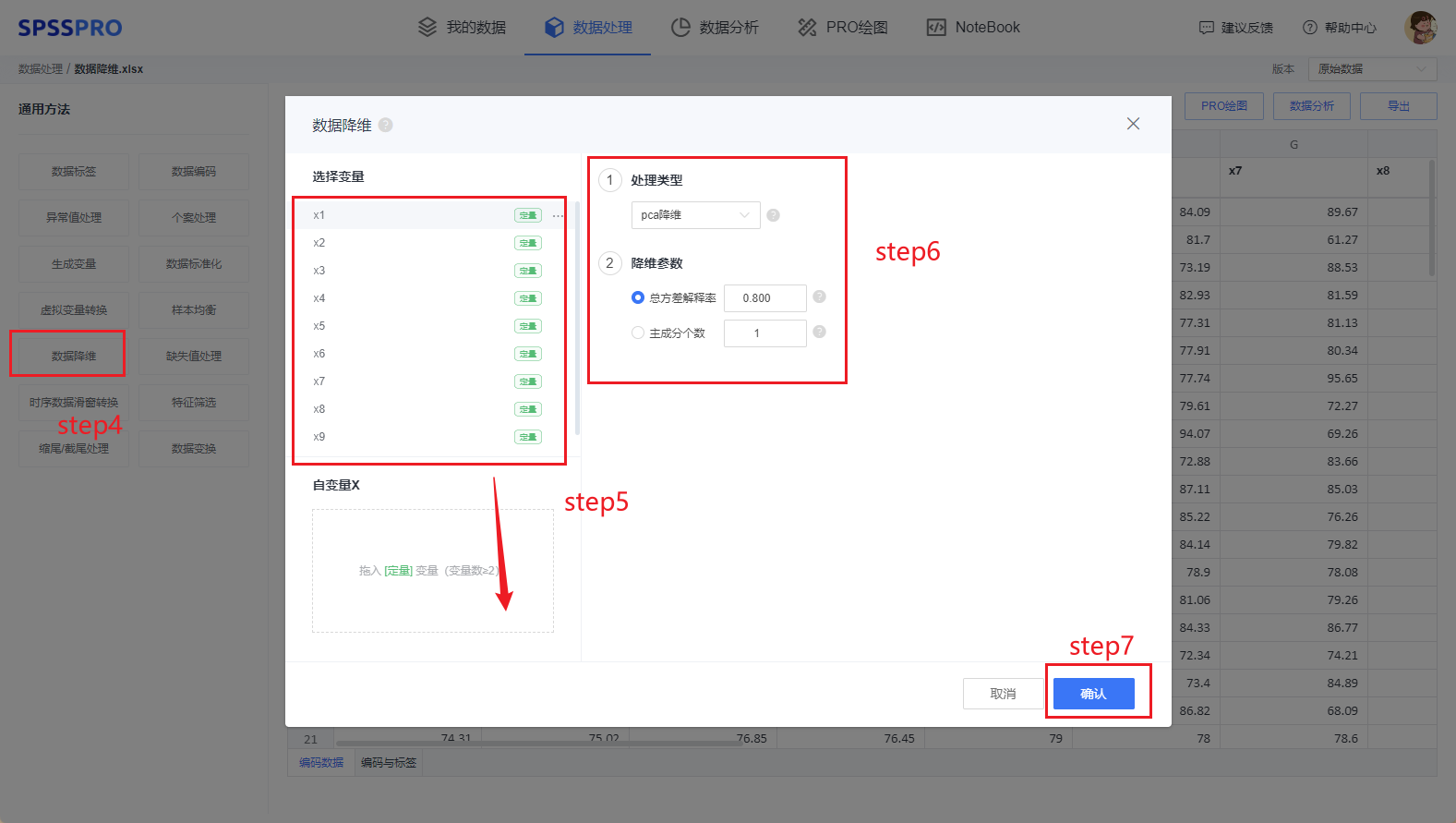
Step4:选择【数据降维】;
Step5:查看对应的数据数据格式,【数据降维】要求变量为定量变量,且至少有两项;
Step6:确认参数,有多种数据降维方法可选择;
Step7:点击【开始处理】,完成全部操作。
# 6、输出结果分析
主成分分析的参数
(1)总方差解释率:方差解释率表示提取的主成分/因子对原有变量的解释能力,方差解释率越大,解释能力越强,越能体现原始变量的关键影响因素,提取的主成分或因子越有效,通常达到80%的程度表现就较为优秀了。比如说现有5个主成分,它们的方差解释率为50%、20%、18%、12%、10%,若总方差解释率设置了80%,前三个主成分的总方差解释率达到了50+20+18=88%,最终降维处理后就是三个变量。
(2)主成分个数:直接确定需要降维为N个主成分,该方法N不得高于原有特征个数。比如说现在有5个变量,主成分设置为3,那么最终降维处理后就是三个变量

数据降维会将原始的10个变量数据整合成4个变量数据,由10个变量到4个变量的过程,我们达到了降维的目的,但是降维过程中或多或少都会损失一些信息,我们选择了主成分分析法,并且总方差解释率定为了0.8,说明降维后的4个变量至少能解释原始数据的80%的信息,即较少地损失了信息又达到降维的目的。
# 7、注意事项
- 数据降维不支持对存在空值的变量进行处理,需要提前处理空值。
# 8、模型理论
(1)pca降维
主成分分析降维,就是一种运用线性代数的知识来进行数据降维的方法,它将多个变量转换为少数几个不相关的综合变量来比较全面地反映整个数据集。这是因为数据集中的原始变量之间存在一定的相关关系,可用较少的综合变量来综合各原始变量之间的信息。这些综合变量称为主成分,各主成分之间彼此不相关,即所代表的的信息不重叠。
(2)线性判别法(LDA)
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想为投影后类内方差最小,类间方差最大,也就是数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
(3)ISOMap
Isomap(Isometric Feature Mapping)是流行学习的一种,通过等距映射的非线性降维,是一种无监督算法。
(4)LLE
局部线性嵌入算法(Locally Linear Embedding,LLE)和Isomap都属于流形学习方法。与Isomap不同的是,LLE在降维中,试图保持邻域内样本之间的线性关系,使得样本之间的映射坐标能够在低维空间中得以保持。
(5)KPCA
KPCA和PCA都是用来做无监督数据处理的,但是有一点不一样。PCA只能是降维,把m维的数据降至k维。KPCA不仅可以降维,也可以升维,把m维的数据升至k维。他们共同的目标都是让数据在目标维度中(线性)可分,即PCA的最大可分性。
(6)t-SNE
t-SNE是一种降维技术,用于在二维或三维的低维空间中表示高维数据集,从而使其可视化,与其他降维算法(如PCA)相比,t-SNE创建了一个缩小的特征空间,相似的样本由附近的点建模,不相似的样本由高概率的远点建模。
# 9、参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.